(WIP) Building a TTRPG atproto feed
This post isn't 100% finished, but I wanted to share what I do have. Check back for more updates or follow me on bluesky to keep up with updates!
I've been running the TTRPG Folks feed on Bluesky for a little bit now, and I've made some changes to the basic feed generator provided by the atproto devs.
Starting on skyfeed
Initially, I started out building the TTRPG folks feed in skyfeed. It was a pretty basic regex feed that used a couple little hacks to make things a bit nicer.
Here is the full regex I started with, but we'll break it down a little bit to cover the hacks.
// The regex
\b#?(ttrpg|d&d|dnd|pathfinder|dungeons\s*and\s*dragons|mork\s*borg|blades\s*in\s*the\s*dark|urban\s*shadows|symbaroum|shadowdark)\b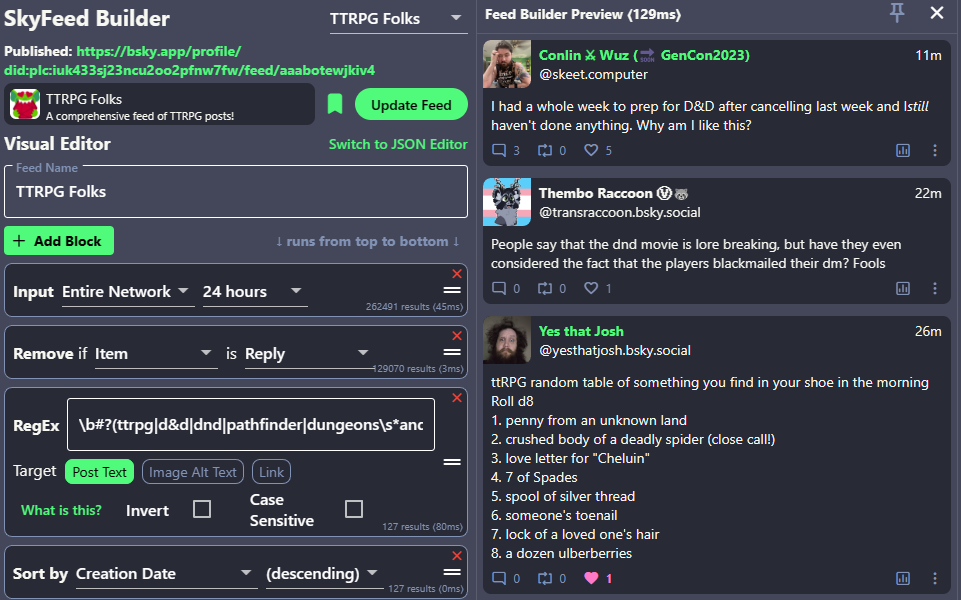
Hack 1: Using word boundaries
If you aren't super familiar with regex, there might be a few confusing aspects to the above code. First, the \b
at the start and end of the regex — these are called word boundaries. They essentially match any number of ways
that a word might be wrapped in a sentence or paragraph. They are considered "anchors" that basically say "does the
following regex exist as a self contained string?".
That means we can match all sorts of things, like these examples:
Just played a game of Dungeons and Dragons.D&D is one of my favorite games!I love being subscribed to the TTRPG Folks feed!Hack 2: Optionally match a hashtag
The next little hack is at the beginning of the regex, where you see #?. This optionally matches a hashtag
letting us match things like these:
This is a hashtag with #ttrpgThis one doesn't have a hashtag with ttrpgTogether with the next hack, this lets us match any words in the main regex regardless of if they are used in a hashtag or not.
Hack 3: Optional spaces
Finally, each word in the regex is spaced with the \s*, instead of an actual " " character. The means we can
match any number of white spaces between the words so all of these are considered the same:
dungeons and dragonsdungeonsanddragons#dungeonsanddragons#DungeonsAndDragonsdungeons and dragonsCombining this with case insensitivity, we can match pretty much any combination of terms folks might use.
A good start, but not exactly what I wanted
In addition to a small outage from skyfeed that took down a ton of feeds on bsky, this regex wasn't able to do some of the more complex stuff I wanted from the feed. I knew I wanted to eventually move to using the "official" feed generator codebase.
Cloning the codebase and deploying to Render
I took a pretty simple approach to getting things setup - forked the feed generator repo and renamed it, before setting up a simple Web Service on Render. The basic free web services on Render should be enough.
Creating a database
I needed a way to store the posts that match our feed from the Firehose. The base feed generator repo uses sqlite, which stores in memory or on disk. Using sqlite would mean setting up a disk with Render or risk losing data anytime the service restarts. Disks are pretty expensive comparatively to hosted databases, so I decided to go with PlanetScale. There is a guide explaining what Planetscale is, but it's pretty complicated - basically the big benefits of Planetscale is that it is a "serverless" database, sharding out your data onto a bunch of different machines and scaling as needed. Instead of hosting a database of a specific size, Planetscale will scale as your service needs. I am using the Hobby tier, which should be more than enough for a long time.
The original feed generator codebase uses Kysely, a tool that makes database connections easy to setup. I used the Planetscale Kysely integration and swapped out the database code. Here is the full file, which we'll break down:
import dotenv from "dotenv";
import { Kysely, Migrator, MysqlDialect } from "kysely";
import { createPool } from "mysql2";
import { DatabaseSchema } from "./schema";
import { migrationProvider } from "./migrations";
import path from "path";
const envPath = path.resolve(__dirname, "../../.env.local");
dotenv.config({ path: envPath });
const dialect = new MysqlDialect({
pool: createPool(process.env.DATABASE_URL ?? ""),
});
export const createDb = async (): Promise<Database> => {
return new Kysely<DatabaseSchema>({
dialect,
});
};
export const migrateToLatest = async (db: Database) => {
const migrator = new Migrator({ db, provider: migrationProvider });
const { error } = await migrator.migrateToLatest();
if (error) throw error;
};
export type Database = Kysely<DatabaseSchema>;Imports
We start by importing everything we need.
dotenvpulls the local env filekyselyhandles the database connection. Planetscale is a Mysql database, so we import the Mysql dialect.mysql2handles actually connecting to the database.
import dotenv from "dotenv";
import { Kysely, Migrator, MysqlDialect } from "kysely";
import { createPool } from "mysql2";
import { DatabaseSchema } from "./schema";
import { migrationProvider } from "./migrations";
import path from "path";Updating the local env
This post is still in progress!